New approach to question answering over structured documents with PDFTriage

Structured documents, such as PDFs, web pages, and presentations, present unique challenges for large language models (LLMs) when it comes to question answering (QA). Addressing this, a recent research paper from Stanford University and Adobe Research has unveiled PDFTriage, a novel approach designed to improve the accuracy and efficiency of LLMs in this domain.
The Problem with Current LLMs
LLMs, despite their vast capabilities, often struggle with document QA when the document exceeds the model's context length. The common workaround is to retrieve relevant context from the document and represent it as plain text. However, this method falls short when dealing with structured documents. Such documents have inherent structures like tables, sections, and pages, and representing them as plain text can lead to incongruities. This often results in the LLM failing to answer seemingly straightforward questions that reference the document's structure.
Introducing PDFTriage
To bridge this gap, the researchers proposed PDFTriage, an approach that allows models to retrieve context based on either the document's structure or its content. PDFTriage provides models with access to metadata about the document's structure, enhancing their ability to answer questions that reference specific parts of the document, such as a particular table or page range.
For instance, consider questions like:
Can you summarize the key takeaways from pages 5-7?
What year [in table 3] has the maximum revenue?
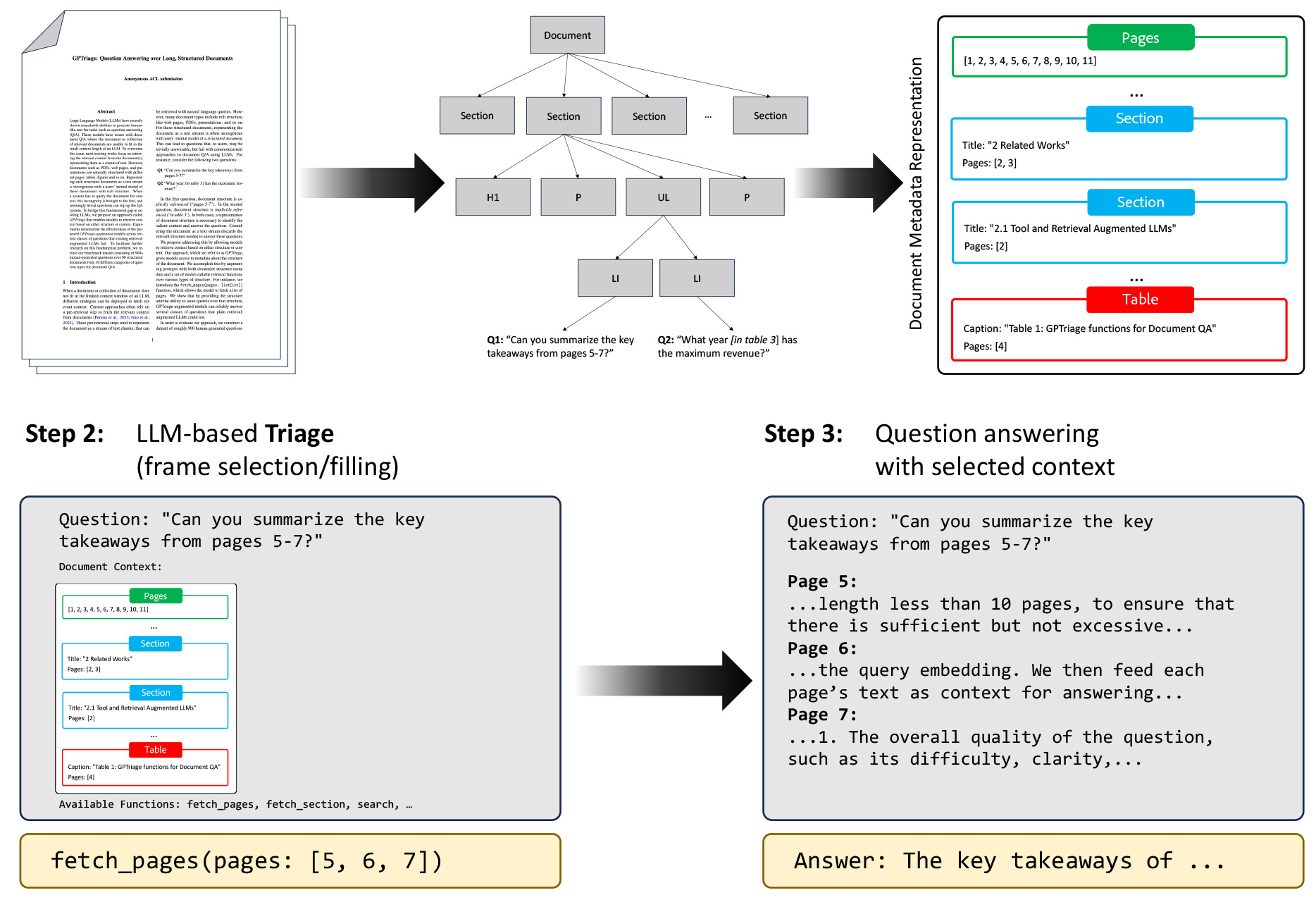
Answering such questions requires a representation of the document's structure. PDFTriage addresses this by introducing functions like `fetch_pages` that allow the model to retrieve specific pages or sections.
Dataset Construction and Evaluation
To evaluate the effectiveness of PDFTriage, the researchers constructed a dataset comprising over 900 human-written questions across 80 structured documents. These questions spanned 10 different categories, including "document structure questions," "table reasoning questions," and even "trick questions."
The dataset was diverse, with questions ranging from single-step answers on a specific document page to multi-step reasoning across an entire document. This comprehensive dataset aimed to test PDFTriage's capability across various real-world, professional settings.
The PDFTriage approach represents a significant step forward in the realm of document QA. By recognizing the importance of a document's structure and providing models with the tools to access and understand this structure, PDFTriage promises more accurate and contextually relevant answers to user queries.
The research team's efforts in constructing a diverse dataset also provide a valuable resource for further studies in this domain. As technology continues to advance, approaches like PDFTriage pave the way for more intuitive and effective interactions between humans and machines.